[CVPR2023] 一篇没有利用传统Siamese Network作为Backbone的3D SOT工作。
Abstract
目标遮挡、传感器能力导致外观信息丢失、点云稀疏,使得3D SOT任务仍具有挑战性。现有方法忽视或裁剪了上下文信息,导致其利用不足。
CXTrack是一种Transformer-based的网络,利用上下文信息提升tracking性能:
- 设计了一个以目标为中心的transformer网络,以连续两帧和前一帧的Bounding Box作为输入,提取点特征,发掘上下文信息,并隐式地传播目标线索
- 提出一种基于Transformer的localization head,通过中心嵌入模块区分目标与干扰项
Introduction
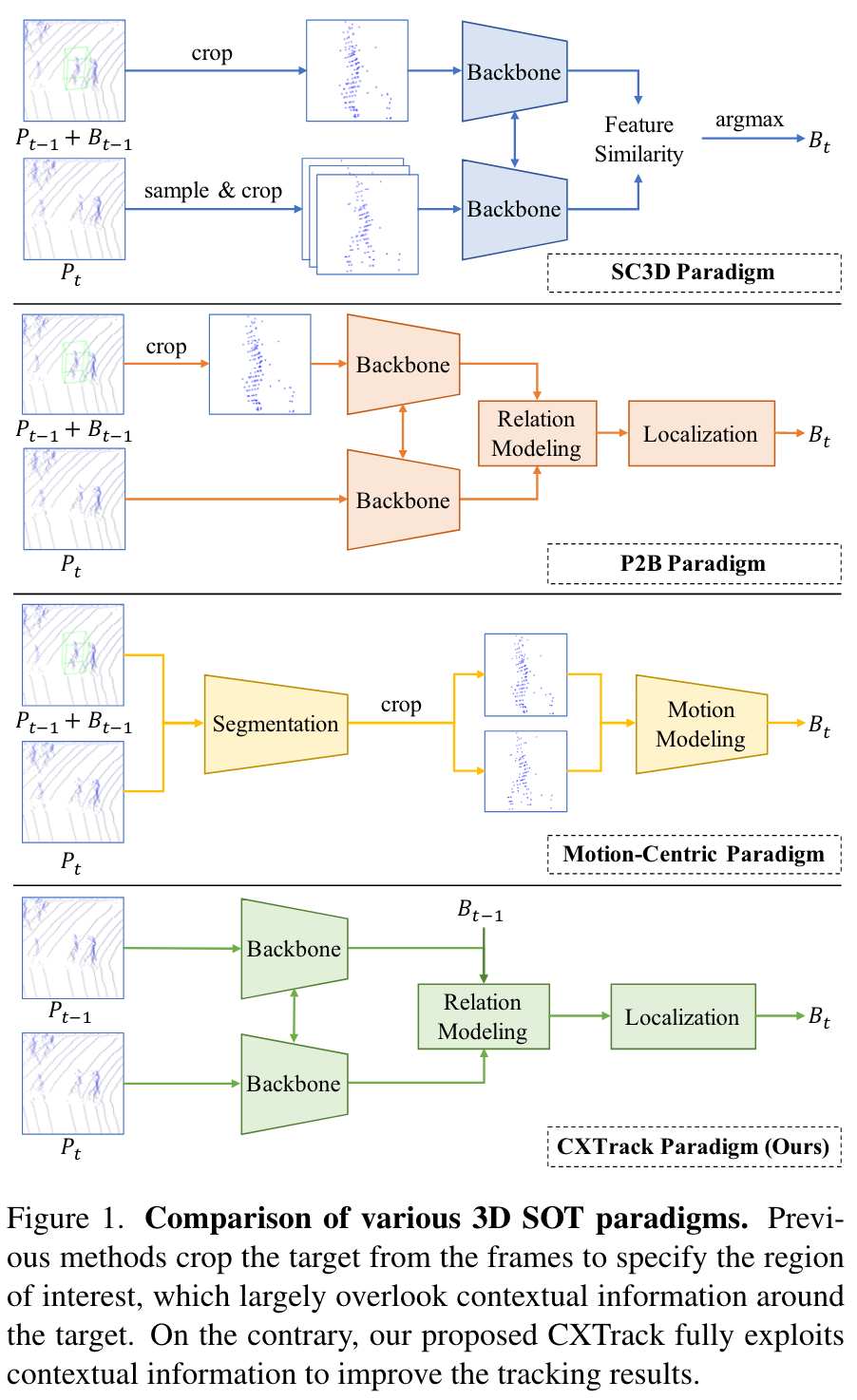
前人工作与CXTrack解决的问题
作者目前的框架分成了三类,SC3D,P2B和motion-centric(运动中心的):
- SC3D从前一帧中裁剪目标,并将目标模版与当前帧中生成的大量潜在候选块进行比较,耗时较多
- P2B解决了效率问题,将前一帧中裁剪的目标模版和当前帧的完整搜索区域作为输入,将目标线索传播到搜索区域,再利用3D RPN预测当前帧中的Bounding Box,达到性能与速度的平衡。这类方法包括(LTTR、V2B、STNet、PTT、MLVSNet、)
但是,上述两种方法完全依赖于目标的外观信息,而忽略了两帧之间的上下文信息。这两种方法对遮挡引起的外观变化很敏感,并倾向于“向内部类干扰项漂移(intra-class distractors drift)”
向内部类干扰项漂移(intra-class distractors drift)
- 在目标跟踪过程中,跟踪算法可能错误地将注意力转移到与目标属于同一类别但并非跟踪目标的其他对象上。这种情况在三维点云跟踪等复杂的视觉跟踪任务中尤为常见,特别是当环境中存在多个相似的对象时。
- 例如,在自动驾驶系统中,如果跟踪算法旨在跟踪一辆特定的汽车,但环境中存在多辆外观相似的汽车,算法可能会错误地将跟踪目标从一辆车误切换到另一辆车。这种情况就是内部类干扰者漂移,它是由于算法未能准确区分目标对象和其他同类对象引起的。
为了解决这个问题,M2-Track引入了一种新的motion-centirc的范式,它直接使用两帧的点云作为输入而不剪切,并随后将目标点从周围环境中分离出来。然后,这些点被剪切,通过显式建模两帧之间的运动来估计当前边界框。但这种范式在后续定位时仍然缺乏上下文信息。
总之,上述方法都没有充分利用到目标周围的上下文信息,来预测当前的边界框。相比之下,CXTrack则能够充分利用连续两帧之间的上下文信息来改善跟踪性能。它直接使用两个连续帧的点云作为输入,用前一帧的边界框指定感兴趣的目标,并预测当前边界框,而无需进行任何剪切,从而在很大程度上保留了上下文信息。
CXTrack的关键步骤
嵌入局部几何信息:首先,使用一个共享的背景网络(backbone network,这里用的是DGCNN)将两个点云的局部几何信息嵌入到点特征中。这意味着,通过这个网络,原始点云中的每个点被转换成包含更丰富信息的特征向量。这一步骤是为了更好地表示和处理点云数据。
集成目标性信息:接着,根据前一帧的边界框(bounding box),将目标性信息(targetness information)集成到点特征中。这里的“目标性信息”指的是每个点是否属于跟踪目标的信息。这有助于区分哪些点属于跟踪目标,哪些点不属于。
目标中心的变换器:采用目标中心的变换器(target-centric transformer)来传播目标线索到当前帧,同时探索目标周围的上下文信息。这个变换器负责处理跟踪任务中的时间序列信息,特别是将上一帧的目标信息传递到当前帧,并考虑目标周围的环境。
X-RPN定位头:增强后的点特征被送入一个名为X-RPN的新型定位头,以获取最终的目标提议。X-RPN使用local transformer来模拟目标内的点特征交互,这在处理大小不同的对象方面比其他定位头更为平衡。换言之,X-RPN能够有效处理目标大小的变化,从而提高定位准确性。
中心嵌入模块:为了区分目标和干扰者,X-RPN中加入了一个新颖的中心嵌入模块,该模块嵌入了两帧之间的相对目标运动信息,用于显式的运动建模。这意味着该模块帮助X-RPN理解目标在连续帧之间的运动,从而更准确地识别和跟踪目标。
CXTrack和前作的一些不同点
- CXTrack认为前作利用给定的边界框从上一帧中裁剪目标,这种做法忽视了两帧之间的上下文信息。
- CXTrack的backbone不是一个siamese network,而是使用的DGCNN提取两个点云的局部几何特征。
方法
targetness mask的概念
作者仿照M2-Track,将前一帧的3D Bounding Box $B_{t-1}$编码为一个targetness mask $\dot{\mathcal{M}}_{t-1}$:
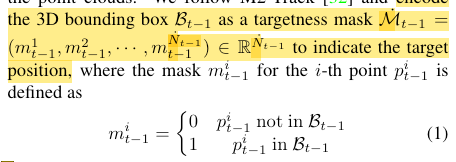
即上一帧点云中,在边界框内的点的mask为1,反之为0(如果在初始状态mask未知,则用0.5填充)。这样,3D SOT任务就被转化为了一个学习以下映射的问题:

CXTrack方法总览
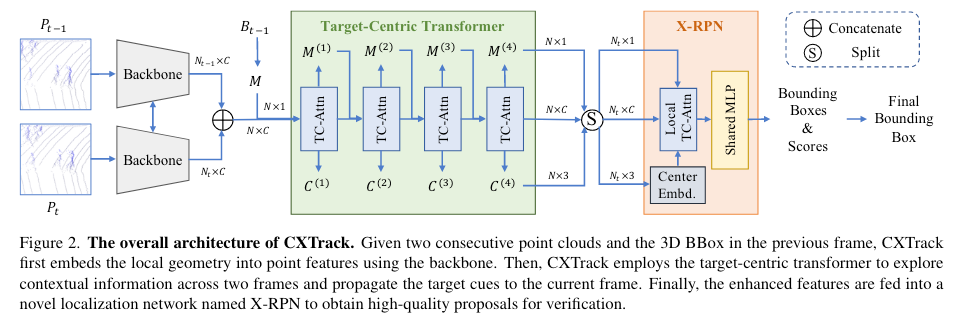
CXTrack首先利用一个分级的特征学习网络作为backbone,将点云的局部几何特征嵌入point feature中。对于两帧的target mask和point feature,对其进行直接拼接concatenate:
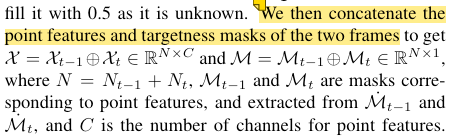
这里要注意$\dot{\mathcal{M}}_{t-1}$和$\mathcal{M}_{t-1}$的区别:
- $\dot{\mathcal{M}}_{t-1}$是原始的targetness mask,直接表示第$t-1$帧中的每个点是否属于跟踪目标。
- $\mathcal{M}_{t-1}$是后续处理中生成的targetness mask的一种形式,经过了某些转换和调整。这里原文说的是“对应于point feature的mask,是从$\dot{\mathcal{M}}_{t-1}$中提取出来的”。具体需要去看代码。
随后,利用target-centric transformer将targetness mask融入point feature中,同时利用到帧之间的上下文信息。最后,利用X-RPN获得target proposal,获得最高targetness score的proposal即为跟踪结果。
Target-Centric Transformer
这一部分用目标周围的上下文信息来增强point feature,同时将目标线索从上一帧传播到当前帧。
这个模块由4个相同的层串联堆叠而成,第$k$层的作用是,对于第$k-1$层输出的point feature $\chi^{(k-1)}$和targetness mask $\mathcal{M}^{(k-1)}$: 首先,使用Layer Normalization
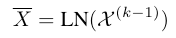
只对于attention的Q和K向量,加入PE,而V向量保持不变。这样做可以让每个精细的point feature更多关注局部几何信息,而不是关联的绝对位置信息(也有可能是作者从实验结果发现只有Q、K加PE效果更好)
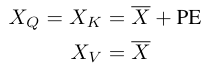
然后,做多头自注意力操作。在级联之前,attention被应用在$h$个子空间中

于是,第$k$层的self-attention层的输出可以写为
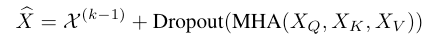
其中第一项是第$k-1$层的输出,第二项为做了attention和dropout处理的输出。随后,再加一层全连接前馈网络对point feature做refine,第$k$层的最终输出为
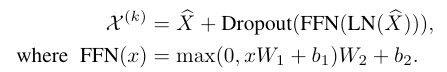
输出$\chi^{(k)}$分为两部分,第一项为self- attention层的输出,第二项对self-attention层的输出又依次做了LN、FFN和Dropout。
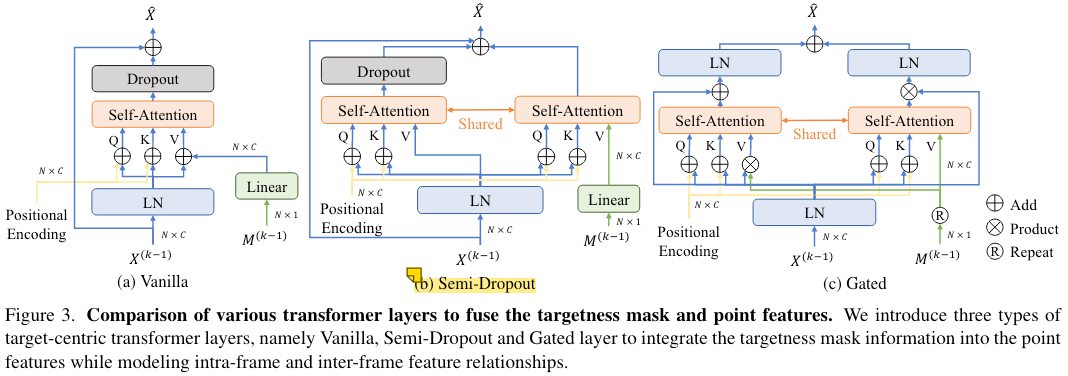
为了向point feature中引入targetness mask,设计了三种不同的魔改transformer层。实验结果表明,Semi-Dropout的设计效果最好,这里重点说说这种结构。
作者认为,targetness mask只能沿attention跨层流动,因此对于小目标(仅有少数几个点要被跟踪),将dropout应用到mask嵌入(也就是Vanilla设计)可能会导致targetness mask的丢失。因此,作者在Semi-Dropout的设计中划分了两个分支,只对没有加入targetness mask的分支做Dropout,而加入targetness mask的分支正常流动:
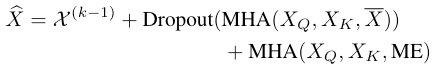
X-RPN
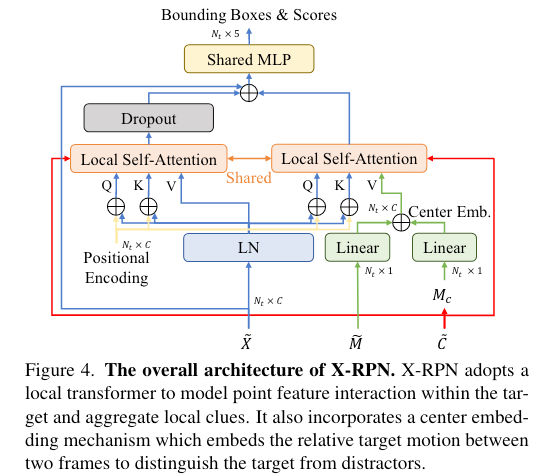
P2B表明,独立的point feature只能捕捉有限的local information,不足以对边界框进行精确回归。因此,作者引入了利用local transformer和center embedding扩展的RPN——X-RPN,作为CXTrack的head。X-RPN直接从point feature中聚合local clues,不需要进行下采样、体素化,避免了信息丢失,在处理大目标与小目标之间达到了平衡。
X-RPN的想法是,点云中的每个点只应该与属于同一目标的点进行交互,从而抑制无关信息。对于target-centric transformer输出的point feature $\chi^{(N_L)}$,targetness mask $M^{(N_L)}$和target center $C^{(N_L)}$,按照空间维度进行分割,并分离出只属于当前帧的信息,送入X-RPN
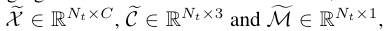
X-RPN首先利用每个点的潜在目标中心计算其邻域
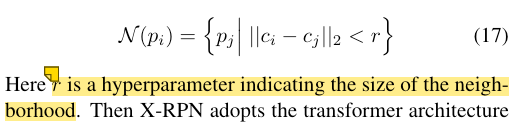
随后,利用target-centric transformer的结构聚合局部信息,这样能够保证每个点只与其邻域内的点交互(这就是为什么叫做local transformer),从而避免了噪声。这里的不同点是,删除了transformer层中的前馈网络,因为仅使用一层attention就足以生辰高质量的target proposal。
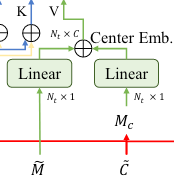
为了解决前面提到的类内干扰项,尤其是对于行人追踪,作者将潜在中心信息和targetness mask相结合。作者认为,两帧之间目标能够保持相似的局部几何信息,且如果连续两帧的持续时间足够短,则目标的位移也较小。因此,作者构造了一个Gaussian proposal-wise mask来表示每个proposal的位移大小。即,对于每个点$p_i$,其预测的目标中心为$c_i$,mask值即为

这个式子的意义是,将基于统计的target center信息(满足高斯分布)嵌入了mask $M_C$中。随后,利用Linear层将mask嵌入到CE矩阵中,实现center和targetness mask的绑定。注意区分这里的Gaussian proposal-wise mask $M_c$和targetness mask $\widetilde{M}$。
Loss Function
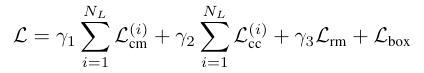
损失函数包含四个部分:
- $\mathcal{L}_{cm}$:衡量transformer每一层预测的$\mathcal{M}^{k}$的loss,CE Loss。
- $\mathcal{L}_{cc}$:衡量每一层预测的target center回归loss。对于行人等非刚体目标,很难回归出一个精确的center。因此,对于非刚体,采用L2 Loss;对于刚体;采用Huber Loss。这里只对gt边界框内的点进行监督。
- $\mathcal{L}_{rm}$:衡量最终预测的targetness mask的loss。和P2B一样,将predict和gt之间距离小于0.3m的视为positive,大于0.3m的视为negative,中间的不监督。CE Loss。
- $\mathcal{L}_{box}$:衡量预测为positive的边界框的loss,Huber Loss。
实验
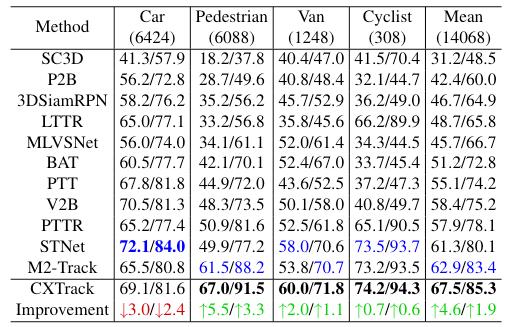
X-RPN中的超参数$\sigma$,移动速度较慢的pedestrian和cyclist设置为固定值,移动速度较快的car和van设置为可学习参数。这符合之前的假设:
“作者认为,两帧之间目标能够保持相似的局部几何信息,且如果连续两帧的持续时间足够短,则目标的位移也较小。因此,作者构造了一个Gaussian proposal-wise mask来表示每个proposal的位移大小”
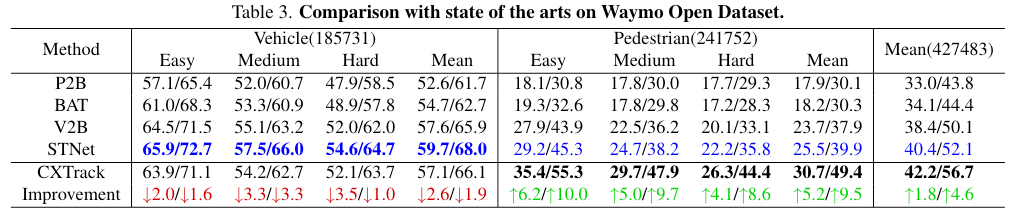
Failure Cases
这篇文章少见的分析了Failure Cases,这是值得学习的。
虽然CXTrack对类内干扰具有鲁棒性,但当点云过于稀疏而无法捕捉信息丰富的局部几何或出现较大的外观变化时,CXTrack无法预测目标的准确方位。 另一方面,中心嵌入直接将目标中心的位移编码为特征,因此如果使用2Hz的数据进行训练,并使用10Hz的数据进行测试,由于位移的尺度差异显著,模型可能会出现性能下降的问题。
文档信息
- 本文作者:焦逸凡
- 本文链接:https://ailovejinx.github.io/2023/11/17/blog-CXTrack/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)